







Strengthen platform reliability across load, dependencies, production conditions.

Enabling critical systems to perform under real-world demand.

To understand system health, dependencies, and failure patterns.

Reduce the risk of releases affecting critical platform behaviours.

Strengthen service behavior and API predictability across changes, dependencies, and release cycles.

Use system-level signals and reliability practices to reduce repeat incidents and improve recovery.

Building release safeguards needed for platform changes affecting high-impact services.

Improve confidence that platform releases can move safely through production environments.
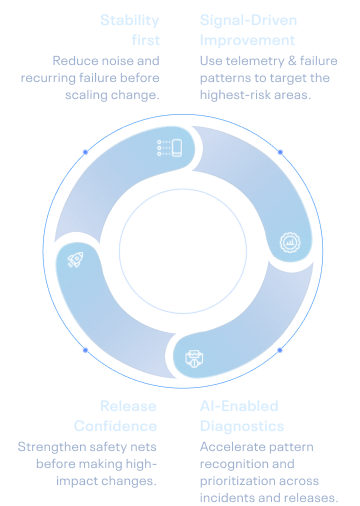
Reduce noise and recurring failure before scaling change.
Use telemetry and failure patterns to target the highest-risk areas.
Accelerate pattern recognition and prioritization across incidents and releases.
Strengthen safety nets before making high-impact changes.




